Kappa architecture was proposed by Jay Kreps (co-creator of Apache Kafka) as a simplification of the Lambda architecture. The core idea: remove the batch layer entirely and treat everything as a stream.
The Core Concept
In Lambda architecture, you maintain two separate processing paths — batch and streaming — which leads to operational complexity. Kappa asks: what if we just used the speed layer for everything?
In Kappa:
- All data is processed as a stream
- Historical reprocessing is done by replaying the stream from the beginning
- A single codebase handles both real-time and historical data
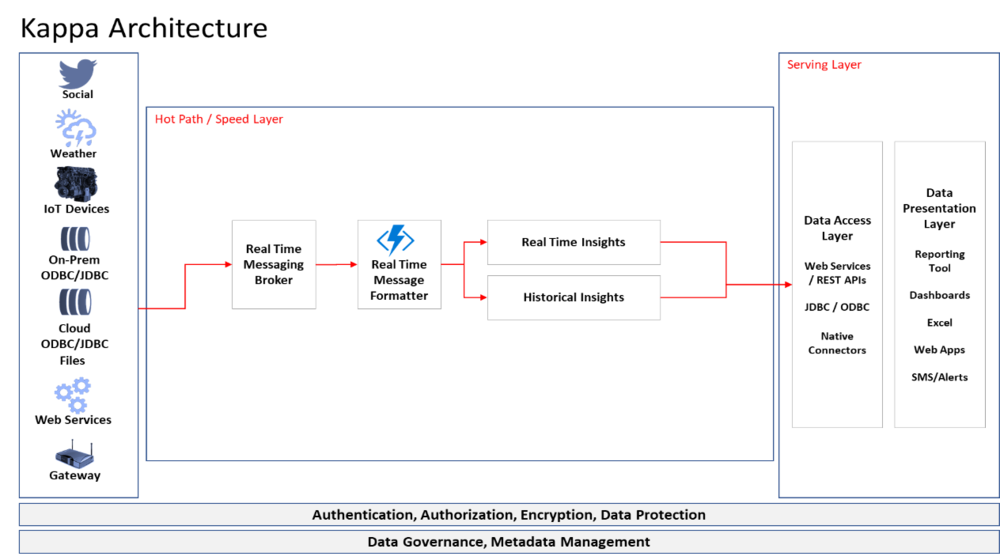
Key Components
Stream Processing Layer: Handles all data processing in real time. Technologies like Apache Kafka, Apache Flink, or Spark Streaming are commonly used.
Serving Layer: Stores the output of stream processing for querying. This can be a database, data warehouse, or any queryable store.
Message Queue / Log: A durable, replayable log (like Kafka) is essential — it allows you to reprocess historical data by replaying from any point in time.
Advantages Over Lambda
- Simpler codebase: One processing path instead of two
- Easier maintenance: No need to keep batch and streaming logic in sync
- Reprocessing: Just replay the stream with updated logic
Trade-offs
- Requires a robust, scalable message queue that can retain data long-term
- May not be as cost-effective for very large historical datasets compared to batch processing on cheap storage
- Latency for full historical reprocessing can be high
When to Use Kappa
Kappa is a good fit when:
- Your use case is primarily stream-oriented
- You want to minimize operational complexity
- You have a reliable, replayable message queue in place
See also: Lambda Architecture and Delta Architecture.